Above average site scrape
If like me you check your site logs most every days, you’ve probably noticed one or two site scrapes. Fortunately most are from the same user (or bot) and use the same, ip, host and browser summary. They grab 20 or so pages in a minute and then stop and come back another day to finish the site off. On a bad day, they might rip the entire site in one pass… With my plugin, targeting those individuals is easier than it used to be; add the browser, host or ip to the block rules in vsf-simple-block and no more annoying user, E.g. host = ‘amazonaws.com’
But the other week, I had another visit by an above average site scraping “team.” I’ve only had about 3 of these types of site scrapes before, so I don’t automatically twig and tend to give the benefit of the doubt.
I happened to be looking at my log, when I saw the first 4 hits shown in the image below. With so little hits, I assumed it was just coincidence that they all had the same browser summary and kept an eye on it. About ten minutes later though, the hits were still coming in. A different url, random ip and host but the same browser summary. Blocking on browser summary isn’t my favourite choice, as it can potentially exclude a lot of users who are completely innocent, but I added the rule to the block plugin and prevented another hour’s worth of hits. When blocked, the number of hits increased three-fold.
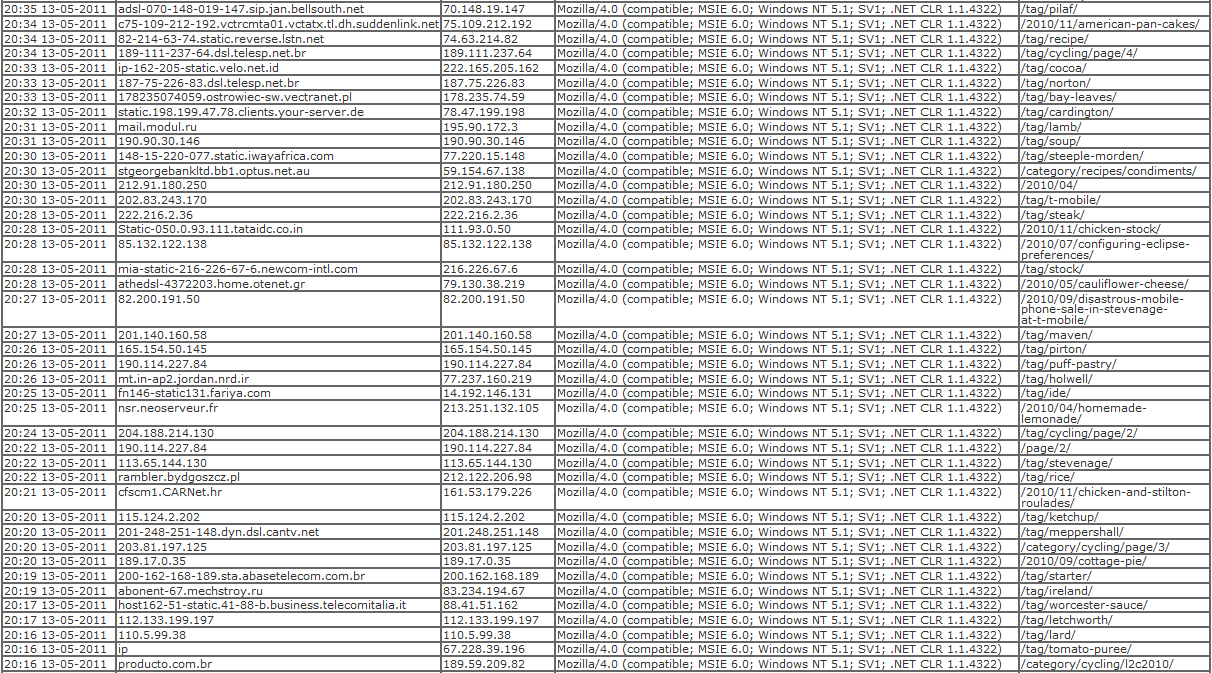
I’m still in the thinking stage on how to code a solution to prevent this type of site scrape. As you can see from the image, between the first hit and the last before being blocked, there is a gap of nineteen minutes. My site doesn’t have a high volume of hits, so all the hits are clumped together. Clumped hits are relatively easy to detect patterns in, but statistically there would be a hit by a genuine user in the middle which would make the logic harder to detect.


Please enable the Disqus feature in order to add comments